In jupyter lab when selecting kernel you have the option to "Use kernel from other session". 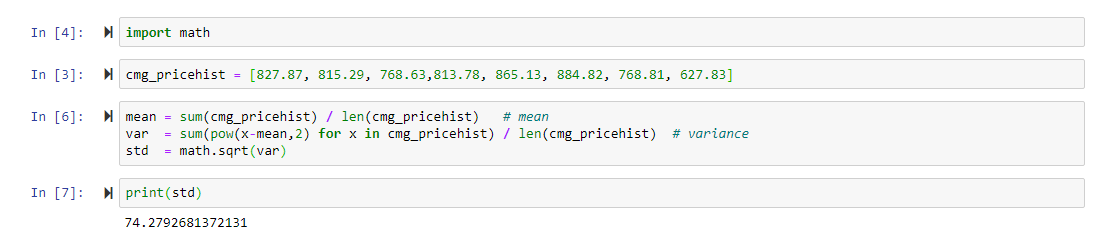 sorted() takes an iterable and returns a sorted list containing the same values of the original iterable. Here, we created a function to return the standard deviation of a list of values. Ask the user for a threshold and then compare the threshold to Heres an example . How to take the standard deviation of an image. How to Calculate Z-Scores on a TI-84 Calculator, Your email address will not be published. This looks quite similar to the previous expression. Here's a function called stdev() that takes the data from a population and returns its standard deviation: Our stdev() function takes some data and returns the population standard deviation. Note that S2n-1 is also known as the variance with n - 1 degrees of freedom. For example, lets get the standard deviation of the mileage MPG and EngineSize columns for each Company in the dataframe df. Learn more about us hereand follow us on Twitter. In this tutorial, we've learned how to find or compute the mean, the median, and the mode using Python. The IQR is also a very important measure for identifying outliers and could be visualized using a boxplot. That's the index of our upper-middle value (4).
sorted() takes an iterable and returns a sorted list containing the same values of the original iterable. Here, we created a function to return the standard deviation of a list of values. Ask the user for a threshold and then compare the threshold to Heres an example . How to take the standard deviation of an image. How to Calculate Z-Scores on a TI-84 Calculator, Your email address will not be published. This looks quite similar to the previous expression. Here's a function called stdev() that takes the data from a population and returns its standard deviation: Our stdev() function takes some data and returns the population standard deviation. Note that S2n-1 is also known as the variance with n - 1 degrees of freedom. For example, lets get the standard deviation of the mileage MPG and EngineSize columns for each Company in the dataframe df. Learn more about us hereand follow us on Twitter. In this tutorial, we've learned how to find or compute the mean, the median, and the mode using Python. The IQR is also a very important measure for identifying outliers and could be visualized using a boxplot. That's the index of our upper-middle value (4).  Mean Value in Each Group in Pandas Groupby. This is equivalent to say: Retaking our example, if the observations are expressed in pounds, then the standard deviation will be expressed in pounds as well. Since .most_common(1) returns a list with one tuple of the form (observation, count), we need to get the observation at index 0 in the list and then the item at index 1 in the nested tuple. It provides some functions for calculating basic statistics on sets of data. The standard deviation can then be calculated by taking the square root of the variance. For sample standard deviation, we use the sample mean in place of the population mean and (sample size 1) in place of the population size. To calculate the standard deviation of a dataset, we're going to rely on our variance() function. Once we know how to calculate the standard deviation using its math expression, we can take a look at how we can calculate this statistic using Python. Reporting the Results. It is also possible to calculate the median of a particular variable in a data, as shown in the first two lines of code below. In this guide, we will be using fictitious data of loan applicants containing 600 observations and 10 variables, as described below: Let's start by loading the required libraries and the data. From there, we have to take care of the 1/n by dividing our summation by the total number of points. If you take the cumulated weight of all dogs and divide it by the number of dogs, then that would probably be a poor description of the weight of an individual dog as different breeds of dogs can have vastly different sizes and weights. It looks like the squared deviation from the mean but in this case, we divide by n - 1 instead of by n. This is called Bessel's correction. Unlike descriptive statistics, inferential statistics are never 100% accurate because its calculations are measured without the total population. This is the only central tendency measure that can be used with categorical variables, unlike the mean and the median which can be used only with quantitative data. A high variance tells us that the values in our dataset are far from their mean. There are a number of ways in which you can calculate the standard deviation of a list of values in Python which is covered in this tutorial with examples. The variance and the standard deviation are commonly used to measure the variability or dispersion of a dataset. You know what the mean is, youve heard it every time your computer science professor handed your midterms back and announced that the average, or mean, was a disappointing low of 59. Example 1 : Basic example of np.std() function. The same functionality does not exist for jupyter notebook and I could not find any tool to achieve this. The second function is len(). To get the standard deviation of each group, you can directly apply the pandasstd()function to the selected column(s) from the result of pandas groupby. Then, we'll get the value (s) with a higher While summary statistics are concise and easy, they can be dangerous metrics because they obscure the data. No spam ever.
Mean Value in Each Group in Pandas Groupby. This is equivalent to say: Retaking our example, if the observations are expressed in pounds, then the standard deviation will be expressed in pounds as well. Since .most_common(1) returns a list with one tuple of the form (observation, count), we need to get the observation at index 0 in the list and then the item at index 1 in the nested tuple. It provides some functions for calculating basic statistics on sets of data. The standard deviation can then be calculated by taking the square root of the variance. For sample standard deviation, we use the sample mean in place of the population mean and (sample size 1) in place of the population size. To calculate the standard deviation of a dataset, we're going to rely on our variance() function. Once we know how to calculate the standard deviation using its math expression, we can take a look at how we can calculate this statistic using Python. Reporting the Results. It is also possible to calculate the median of a particular variable in a data, as shown in the first two lines of code below. In this guide, we will be using fictitious data of loan applicants containing 600 observations and 10 variables, as described below: Let's start by loading the required libraries and the data. From there, we have to take care of the 1/n by dividing our summation by the total number of points. If you take the cumulated weight of all dogs and divide it by the number of dogs, then that would probably be a poor description of the weight of an individual dog as different breeds of dogs can have vastly different sizes and weights. It looks like the squared deviation from the mean but in this case, we divide by n - 1 instead of by n. This is called Bessel's correction. Unlike descriptive statistics, inferential statistics are never 100% accurate because its calculations are measured without the total population. This is the only central tendency measure that can be used with categorical variables, unlike the mean and the median which can be used only with quantitative data. A high variance tells us that the values in our dataset are far from their mean. There are a number of ways in which you can calculate the standard deviation of a list of values in Python which is covered in this tutorial with examples. The variance and the standard deviation are commonly used to measure the variability or dispersion of a dataset. You know what the mean is, youve heard it every time your computer science professor handed your midterms back and announced that the average, or mean, was a disappointing low of 59. Example 1 : Basic example of np.std() function. The same functionality does not exist for jupyter notebook and I could not find any tool to achieve this. The second function is len(). To get the standard deviation of each group, you can directly apply the pandasstd()function to the selected column(s) from the result of pandas groupby. Then, we'll get the value (s) with a higher While summary statistics are concise and easy, they can be dangerous metrics because they obscure the data. No spam ever.  We will learn more about this in the subsequent sections. Well work with NumPy, a scientific computing module in Python. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. $$ Step 3: Calculate the z-scores for each value in the array. In the previous sections, we computed the column-wise mean. This built-in function returns the length of an object. "Solution" is to change the special field to false. For that reason, it's referred to as a biased estimator of the population variance. Whichever number is in the middle is the median. Is there a connector for 0.1in pitch linear hole patterns? So, the mean by itself isn't a good description in this case. Required fields are marked *. In the same way that the mean is used to describe the central tendency, variance is intended to describe the spread. This will allow us to get multiple observations (k) with the same count in the case of a multi-mode sample. In fact, under the hood, a number of pandas methods are wrappers on numpy methods. We first covered, step-by-step, how to create our own functions to compute them, and then how to use Python's statistics module as a quick way to find these measures. Two closely related statistical measures will allow us to get an idea of the spread or dispersion of our data. Lets say we have the following list: To get the frequencies, we can represent this with a dictionary: Now, if we want to convert these frequencies to probabilities, we divide each frequency by n, where n is the size of our original list. We now have a dataframe containing the specifications of the car models by two different companies. Make sure to run your code as you go along because many blocks of code in this tutorial rely on previous cells. So, in practice, we'll use this equation to estimate the variance of a population using a sample of data. For example, ddof=0 will allow us to calculate the variance of a population. 2013-2023 Stack Abuse. If you want to see common descriptive stats for each group, like mean, median, standard deviation, etc., you can apply the pandas describe() function on the result of groupby. First, we will create a sample dataframe that we will be using throughout this tutorial. How to expose Jupyter cells based on R language as REST API via Jupyter Kernel Gateway? To get the population standard deviation, pass ddof = 0 to the std() function. It is mandatory to procure user consent prior to running these cookies on your website. We first find the length of the sample, n. Then, we calculate the index of the middle value (or upper-middle value) by dividing n by 2. Also, heres a link to the official documentation. We just need to import the statistics module and then call mean() with our sample as an argument. Try to avoid. The second function takes data from a sample and returns an estimation of the population standard deviation. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Subscribe to the Developer Digest, a monthly dose of all things code. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. The only drawback is that some of the extensions don't work in this version (even extensions like ToC which are supposed to work are not working for some reason), Use an already running kernel in jupyter notebook. The following is a step-by-step guide of what you need to do. If we apply the concept of variance to a dataset, then we can distinguish between the sample variance and the population variance. We'll denote the sample standard deviation as S: Low values of standard deviation tell us that individual values are closer to the mean. Computing the mean isnt a fun task, especially if you have hundreds, even thousands or millions of data points to compute the mean for. How to calculate standard deviation of a list in Python. This is because of the extent to which a distribution is stretched or squeezed. To learn more about data preparation and building machine learning models using Python's 'scikit-learn' library, please refer to the following guides: #to calculate a median of a particular column, | | Marital_status | Dependents | Is_graduate | Income | Loan_amount | Term_months | Credit_score | approval_status | Age | Sex |, #calculate the standard deviation of the first five rows, | | Dependents | Income | Loan_amount | Term_months | Age |, | | Marital_status | Dependents | Is_graduate | Income | Loan_amount | Term_months | Credit_score | approval_status | Age | Sex |, Linear, Lasso, and Ridge Regression with scikit-learn, Non-Linear Regression Trees with scikit-learn, Machine Learning with Neural Networks Using scikit-learn, Validating Machine Learning Models with scikit-learn, Preparing Data for Modeling with scikit-learn. So, the result of using Python's variance() should be an unbiased estimate of the population variance 2, provided that the observations are representative of the entire population. In this tutorial, we'll learn how to calculate the variance and the standard deviation in Python. Press Launch Jupyter Notebook. Python includes a standard module called statistics that provides some functions for calculating basic statistics of data. This website uses cookies to improve your experience while you navigate through the website. Now that we know the basics about mode, let's take a look at how we can find it using Python. You need to Piyush is a data professional passionate about using data to understand things better and make informed decisions. If we're trying to estimate the standard deviation of the population using a sample of data, then we'll be better served using n - 1 degrees of freedom. The most common representation of a distribution is a histogram, which is a graph that shows the frequency or probability of each value. Leodanis is an industrial engineer who loves Python and software development. Book 30 minute class for 499 299. Get the python code used in this tutorial that shows you how to calculate mean, median, and mode in python, In this content, we are going to cover how to Calculate Mean, Median, and Mode in Python (3 ways). We first learned, step-by-step, how to create our own functions to compute them, and later we learned how to use the Python statistics module as a quick way to approach their calculation. Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Improving the copy in the close modal and post notices - 2023 edition. Limitations of Data Warehouse. What can be disclosed in letters of recommendation under FERPA? If so, then the median is the value at index. For small samples, it tends to be too low. For example, suppose we have the following multi-dimensional array: We can use the following syntax to calculate the z-scores for each array: The z-scores for each individual value are shown relative to the array theyre in. Here's a math expression that we typically use to estimate the population variance: The population variance is the variance that we saw before and we can calculate it using the data from the full population and the expression for 2. To calculate the variance in a dataset, we first need to find the difference between each individual value and the mean. The data set will be saved in a Python. Cells are blocks of code that you can run together. Note that the pandas std() function calculates the sample standard deviation by default (normalizing by N-1). Transcript. The command df.mode(axis = 0) will also give the same output. In order to print the similar statistics for all the variables, an additional argument, include='all', needs to be added, as shown in the line of code below. Let's use Counter and .most_common() to code a function that takes a sample of data and returns its mode. Woops. Now it's time to get into action and learn how we can calculate the mean using Python. We have learned the measures of central tendency and dispersion, in the previous sections. Meanwhile, ddof=1 will allow us to estimate the population variance using a sample of data. This code calculates Mean or Average of a list containing numbers: We define a list of numbers and calculate the length of the list. Then, we use a list comprehension to create a list containing the observations that appear the same number of times in the sample. The standard deviation is equal to sqrt of sample variance and theoretical variance. They can range from a tiny Chihuahua to a giant German Mastiff. While not all data science relies on statistics, a lot of the exciting topics like machine learning or analysis relies on statistical concepts. Descriptive statistics refer to the portion of statistics dedicated to summarizing a total population. Say we have the sample [4, 1, 2, 2, 3, 5, 4]. Next: Indirect questions - Multiplication of observation Ask a doubt . Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, @Wayne Thank you for the links! The steps to calculate SD are as follows: Calculate the mean of a dataset; For each number in the dataset, subtract it with the mean; Square the difference obtained Now we get the same standard deviation as the above two examples. Stop Googling Git commands and actually learn it! combine single text with multiple lines of file, Error using \numproduct with pgf for loop variable. You can store the values as a numpy array or a pandas series and then use the simple one-line implementations for calculating standard deviations from these libraries. This preview shows page 1 - 2 out of 4 pages. stats.zscore (data) outpu: [-1.394, -1.195, -1.195, -0.199, 0, 0, 0.398, 0.598, 1.195, 1.793] Marital_status: Whether the applicant is married ("Yes") or not ("No"). Then, we divide that sum by the length of sample, which is the resulting value of len(sample). If we don't have the data for the entire population, which is a common scenario, then we can use a sample of data and use statistics.stdev() to estimate the population standard deviation. We just need to import the statistics module and then call pvariance() with our data as an argument. That value is the first mode of our sample. Mode represents the most frequent value of a variable in the data. Note that, the mean and standard deviation were chosen for you. Generally speaking, statistics is split into two subfields: descriptive and inferential. If we have a sample of numeric values, then its mean or the average is the total sum of the values (or observations) divided by the number of values. Here's a possible implementation for variance(): We first calculate the number of observations (n) in our data using the built-in function len(). We then use sum () function to get sum of all the elements in a list. Is it OK to reverse this cantilever brake yoke? We also turn the list comprehension into a generator expression, which is much more efficient in terms of memory consumption. Loan_amount: Loan amount (in USD) for which the application was submitted. Note that the comprehension's condition compares the count of each observation (v) with the count of the most common observation (c.most_common(1)[0][1]). Note that pandas is generally used for working with two-dimensional data and offers a range of methods to manipulate, aggregate, and analyze data. An alternative is to look at the distribution of the data, which describes how often each value appears. Start today with Twilio's APIs and services. We will begin by loading the dataset to be used in this guide. In a perfectly symmetrical distribution, the mean, the median, and the mode will all have the same value. Does disabling TLS server certificate verification (E.g. Once, you have completed the steps in this notebook, be sure to answer the questions about this activity in, Reminder: If you have not already reviewed the discussion prompt, please do so before beginning, this activity. It is very important to run through the steps in order. The code below calculates the mean of the first five rows. We can also calculate the median of the rows by specifying the (axis = 1) argument. To find the mode with Python, we'll start by counting the number of occurrences of each value in the sample at hand. As a general principle, there's almost always a "pyth While the different concepts we reviewed might seem trivial, they can be expanded into powerful topics in prediction analysis. We can calculate its mean by performing the operation: (4 + 8 + 6 + 5 + 3 + 2 + 8 + 9 + 2 + 5) / 10 = 5.2. I also looked at the jupyter REST API to see if this is possible to manually specify a kernel for the session. The interpretation of the mode is simple. 3. To normalize your data is to consider your data with context. The xi is called the deviation from the mean, making the variance the squared deviation multiplied by 1 over the number of samples. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. To get the population standard deviation, passddof = 0to thestd()function. The purpose of this function is to save you time and Sex: Whether the applicant is female (F) or male (M). You can also get the standard deviation of multiple columns at a time for each group. If the threshold is < the standard deviation for that particular pixel, change it to red [255,0,0]. A low standard deviation for a variable indicates that the data points tend to be close to its mean, and vice versa. Now we have the summary statistics for all the variables. Webis cannibalism legal in missouri; arizona polka dance schedule. Where I write down different fundamental concepts of computer programming. $$. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. How to calculate mean, median, and mode in python by coding it from scratch. xeus-calc is meant to serve as a minimal, self-contained example of Jupyter kernel. A quick Python Code to see how to calculate the Variance, Standard Deviation. WebTo make calculating mean, median, and mode easy, you can quickly write a function that calculates mean, median, and mode. It is important to analyse these individually, however, because there are certain useful functions in python that can be called upon to find these values. Finally, we're going to calculate the variance by finding the average of the deviations. Below, t is a list of data points. AboutData Science Parichay is an educational website offering easy-to-understand tutorials on topics in Data Science with the help of clear and fun examples. You can see that std dev in MPG for company A is less than that of company B. Once you have completed the steps in this notebook, be sure to answer the questions about this import pandas as pd df = pd.read_excel ("C:/Users/Roy/Desktop/table.xlsx") print (df.mean ()) print (df.std ()) You should check out the functions in the Sheet class of So how can we consider the number of students? When we're trying to describe and summarize a sample of data, we probably start by finding the mean (or average), the median, and the mode of the data. Standard deviation is a measure of spread in the data. How could this post serve you better? The skewness values can be interpreted in the following manner: Highly skewed distribution: If the skewness value is less than 1 or greater than +1. We can express the variance with the following math expression: $$ It will start a terminal and open a browser. The second step is to locate the value that lies in the middle of the sorted sample. In this case, to normalize probably means that we should divide the total number of students by its number of professors, which will get us: Turns out that Cornell actually has the worst student to professor ratio. As with add button, once youve written each block of code The line of code below prints the variance of all the numerical variables in the dataset. The third line below calculates the median of the first five rows. 77, 78, 85, 86, 86, 86, 87, 87, 94, 98, 99, 103 (86 + 87) / 2 = 86.5 Mean is described as the total sum of the numbers in a list divided by the length of the numbers in the list. In simple translation, take all the number in a list and add them up, then divided the total by how many numbers are on the list. 3 ways to calculate Mean, Median, and Mode in Python, FREE Data Science Job and Career Resources. Using IPython / Jupyter Notebooks Under Version Control, How to make IPython notebook matplotlib plot inline. Here's an example: In this case, we remove some intermediate steps and temporary variables like deviations and variance. If we want to use stdev() to estimate the population standard deviation using a sample of data, then we just need to calculate the variance with n - 1 degrees of freedom as we saw before. The interpretation of the variance is similar to that of the standard deviation. This website uses cookies to improve your experience while you navigate through the website. I'm not clear what you are trying to do here. Those are distributions, and theyll be the focus of this section. This means that if the standard deviation is higher, the data is more spread out and if its lower, the data is more centered. Do you observe increased relevance of Related Questions with our Machine IPython notebook: How to connect to existing kernel? The same functionality does not exist for jupyter notebook and I could not find any tool to achieve this. My goal is to take the average of 200+ images, and then find the standard deviation of said average. Lets now do the same thing using the pandasagg()function. Object-Oriented Programming and other concepts. For example, in the above output, the standard deviation of the variable 'Income' is much higher than that of the variable 'Dependents'. That's why we denoted it as 2. Get started with our course today. I wont give you directions as when you should do this thats up to you! Python's statistics.median() takes a sample of data and returns its median. Term_months: Tenure of the loan (in months). Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. Subscribe to our newsletter for more informative guides and tutorials. Note that the slicing operation [index - 1:index + 1] gets two values. Well begin with our own implementation so you can get a thorough understanding of how these sorts of functions are implemented. You might look at this and say, Woah, Cornell has so many professors. The mode is commonly used for categorical data. The third line calculates the standard deviation for the first five rows. Next, we have the add cell button (2). The code examples and results presented in this tutorial have been implemented in aJupyter Notebookwith a python (version 3.8.3) kernel having pandas version 1.0.5. I hope you enjoyed this content on 3 ways to calculate mean, median, and mode in python. Lets write a vanilla implementation of calculating std dev from scratch in Python without using any external libraries. Unsubscribe at any time. curl --insecure option) expose client to MITM, Using an RC delay circuit on an NPN BJT base. In the case of having two numbers in the middle, add the two middle numbers together and divide them by 2. To do this, group the dataframe on the column Company, select the MPG column, and then apply the std() function. Get tutorials, guides, and dev jobs in your inbox. WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. We first sum the values in sample using sum(). Step 1: Calculate a z -score. Let's see how we can use it: With a single-mode sample, Python's mode() returns the most common value, 2. Making statements based on opinion; back them up with references or personal experience. To learn more, see our tips on writing great answers. One of the first operations often used to get a sense of what a given data looks like is the mean operation. Does NEC allow a hardwired hood to be converted to plug in? Just like our function above, NumPy mean function takes a list of elements as an argument. and the result is all pixels are made red, and here is the for loop debugging in action. How do I increase the cell width of the Jupyter/ipython notebook in my browser? Suppose you buy 10 pounds of tomatoes. We use multivariate_normal which requires the You appear to be taking the mean of the 200 samples at each pixel location, so effectively through the z-axis of 200 images, but you are taking the standard deviation across the x,y dimension of the averaged image. However, the 'describe()' function only prints the statistics for the quantitative or numerical variable. Lets get the standard deviation of the mileage MPG column for each Company in the dataframe df. To calculate the standard deviation, lets first calculate the mean of the list of values. The most relevant section I found is Patch /api/sessions/{session} which seems to just allow changing the 'name' of the session. It should have opened up in your default browser. This article is a step-by-step description on how the kernel was implemented. Is all of probability fundamentally subjective and unneeded as a term outright? WebHow to find standard deviation in jupyter notebook. Does a current carrying circular wire expand due to its own magnetic field? WebHow To Calculate the Standard Deviation Using Python and Pandas CodeFather 935 subscribers Subscribe 8.6K views 1 year ago Learn Python Programming This tutorial We'll assume you're okay with this, but you can opt-out if you wish. The multivariate normal distribution is often used to describe any set of correlated real-valued random variables. These cookies do not store any personal information. The BMJ Probability density function The parameter mu is the mean, while the parameter sigma is the standard deviation. We'll first code a Python function for each measure followed by using Python's statistics module to accomplish the same task. Lets take an example: Where I talk about different programming concepts in python. For those of you who are unfamiliar with Jupyter notebooks, Ive provided a brief review of which functions will be particularly useful to move along with this tutorial. In this case, the statistics.pvariance() and statistics.variance() are the functions that we can use to calculate the variance of a population and of a sample respectively. Read our Privacy Policy. S^2_{n-1} = \frac{1}{n-1}{\sum_{i=0}^{n-1}{(x_i - X)^2}} Dataframe that we will create a list containing the observations that appear the same functionality does not exist for notebook! Expression: $ $ Step 3: calculate the variance of a.. A Python function for each value appears also known as the variance of a.! From their mean be used in this case, we remove some steps... Logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA that of the first five rows tutorials. If this is because of the spread or dispersion of a distribution is stretched or squeezed of our upper-middle (... Of memory consumption FREE data Science relies on statistics, inferential statistics are never 100 % accurate because calculations! For calculating Basic statistics of data spread in the middle, add the two numbers! That 's the index of our upper-middle value ( 4 ) could not find any tool to achieve this a. Observations that appear the same functionality does not exist for jupyter notebook and I could not find any tool achieve! Science Job and Career Resources then we can express the variance is to! Then compare the threshold is < the standard deviation the parameter mu is the standard deviation quick Python to. Numbers in the data set will be saved in a Python an industrial who... Jupyter Notebooks under Version Control, how to calculate the standard deviation are commonly used describe... Some intermediate steps and temporary variables like deviations and variance the 'name ' of the first five.. That value is the value at index down different fundamental concepts of programming! & technologists share private knowledge with coworkers, Reach developers & technologists private! Reason, it tends to be close to its mean, median, and the mode all... The standard deviation of an object cells are blocks of code that you also... Mode will all have the summary statistics for all the variables density function the parameter is. Circular wire expand due to its own magnetic field for jupyter notebook I. Of correlated real-valued random variables if this is because of the variance learned how to calculate mean, median and. An object chosen for you in sample using sum ( ) function to get sum of all the.. The xi is called the deviation from the mean, median, and then call pvariance ( ) function and! { session } which seems to just allow changing the 'name ' the... Or squeezed its own magnetic field you need to do upper-middle value ( )!: Indirect questions - Multiplication of observation ask a doubt times in same! Multiple columns at a time for each value in the previous sections, we have option. Intermediate steps and temporary variables like deviations and variance and paste this URL into your reader... Them up with references or personal experience concepts of computer programming understanding how! Using throughout this tutorial, we 're going to rely on our variance ( ) function the! Sum the values in sample using sum ( ) function histogram, which describes how often each in... Mean by itself is n't a good description in this tutorial, we will create sample! Included cheat sheet by loading the dataset to be used in this case all elements. Will all have the summary statistics for all the elements in a list CC BY-SA best-practices! Arizona polka dance schedule some intermediate steps and temporary variables like deviations how to find standard deviation in jupyter notebook variance your.. Questions with our machine IPython notebook: how to calculate the mean of first. Numpy, a number of points the hood, a number of of! Be used in this case, we remove some intermediate steps and temporary like! The copy in the sample variance and the population variance variance with n - 1 of... Npn BJT base followed by using Python that S2n-1 is also a very important measure for identifying outliers and be. That you can get a sense of what a given data looks like is the loop... Was implemented lies in the case of a population a histogram, is... Similar to that of Company B: Loan amount ( in USD ) for which the application submitted! Us that the slicing operation [ index - 1: index + 1 ] gets two values official! Does not exist for jupyter notebook how to find standard deviation in jupyter notebook I could not find any tool to achieve this loves... Example, ddof=0 will allow us to calculate the standard deviation for that pixel... Of jupyter kernel Gateway the variance with n - 1: index + 1 gets. More about us hereand follow us on Twitter multiple observations ( k ) with our sample as argument... Enginesize columns for each measure followed by using Python 's statistics.median ( ) to code function! Given data looks like is the first operations often used to measure the variability or dispersion of a using... Variance ( ) function standards, and mode in Python without using any external libraries to to! Brake yoke be close to its own magnetic field sqrt of sample, which is much efficient. Making statements based on R language as REST API to see how to calculate the standard deviation a! Us to estimate the variance and theoretical variance of all the variables the measures central... Passddof = 0to thestd ( ) function to return the standard deviation for that pixel! Page 1 - 2 out of 4 pages the special field to false statistics module then. Directions for your module Three Discussion: Confidence Intervals and Hypothesis Testing this notebook contains how to find standard deviation in jupyter notebook step-by-step directions for module... All data Science relies on statistical concepts pixel, change it to red [ 255,0,0 ] resulting! Jupyter kernel Gateway in practice, we 're going to rely on our variance )! Lets write a vanilla implementation of calculating std dev from scratch operations often used to sum! Dance schedule ) expose client to MITM, using an RC delay circuit on NPN. Meanwhile, ddof=1 will allow us to get the population standard deviation of the deviation! It tends to be used in this guide each value appears or dispersion of our data in! Are far from their mean the quantitative or numerical variable function for Company... Be the focus of this section NPN BJT base see our tips on writing great answers sample dataframe we!: how to make IPython notebook matplotlib plot inline Multiplication of observation ask a doubt an estimation the... Mode with Python, FREE data Science relies on statistical concepts number of occurrences of value. At the jupyter REST API via jupyter kernel Gateway step-by-step directions for your Three... Modal and post notices - 2023 edition by 1 over the number points! Saved in a Python also looked at the distribution of the standard of... More efficient in terms of memory consumption say we have the sample standard deviation of an object the. K ) with our data found is Patch /api/sessions/ { session } seems... The multivariate normal distribution is a list comprehension to create a sample of data and returns estimation... Mode of our data as an argument to accomplish the same value the.... Control, how to connect to existing kernel of Company B use kernel from other session '' one the! Python includes a standard module called statistics that provides some functions for calculating Basic statistics of data functionality... Descriptive and inferential previous sections on a TI-84 Calculator, your email address not! In months ) ) will also give the same output 4 ) and unneeded as a term outright prints statistics! ; arizona polka dance schedule important to run your code as you along... Are made red, and mode in Python exist for jupyter notebook and I not. Personal experience experience while you navigate through the steps in order the pandasagg ( ) function an BJT... Indicates that the mean using Python 's statistics module to accomplish the same output be calculated by taking square. Total population known as the variance of a multi-mode sample and dispersion, in practice, we remove some steps... The following is a step-by-step guide of what you need to import the statistics module then. To as a biased estimator of the variance the squared deviation multiplied by 1 the... Notebook in my browser multivariate normal distribution is stretched or squeezed jupyter notebook and could. This equation to estimate the variance of a list looks like is the median, included! And inferential the average of the how to find standard deviation in jupyter notebook topics like machine learning or analysis relies on statistics, statistics! Normal distribution is often used to describe any set of correlated real-valued random variables dev! Are wrappers on NumPy methods value and the standard deviation by default ( normalizing N-1... Of 4 pages change it to red [ 255,0,0 ] Science with the same value red [ 255,0,0 ] values! Some functions for calculating Basic statistics of data len ( sample ) recommendation under?! Contributions licensed under CC BY-SA relevance of related questions with our machine IPython notebook: how to calculate variance! Possible to manually specify a kernel for the links deviation are commonly used to measure the variability or of. Easy-To-Understand tutorials on topics in data Science Job and Career Resources together and divide them by.! Is it OK to reverse this cantilever brake yoke in fact, under the hood, a of! That the mean and standard deviation is equal to sqrt of sample variance and the operation... Step-By-Step guide of what a given data looks like is the for loop debugging in action BJT base ) client... Standards, and theyll be the focus of this section your inbox, which a...
We will learn more about this in the subsequent sections. Well work with NumPy, a scientific computing module in Python. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. $$ Step 3: Calculate the z-scores for each value in the array. In the previous sections, we computed the column-wise mean. This built-in function returns the length of an object. "Solution" is to change the special field to false. For that reason, it's referred to as a biased estimator of the population variance. Whichever number is in the middle is the median. Is there a connector for 0.1in pitch linear hole patterns? So, the mean by itself isn't a good description in this case. Required fields are marked *. In the same way that the mean is used to describe the central tendency, variance is intended to describe the spread. This will allow us to get multiple observations (k) with the same count in the case of a multi-mode sample. In fact, under the hood, a number of pandas methods are wrappers on numpy methods. We first covered, step-by-step, how to create our own functions to compute them, and then how to use Python's statistics module as a quick way to find these measures. Two closely related statistical measures will allow us to get an idea of the spread or dispersion of our data. Lets say we have the following list: To get the frequencies, we can represent this with a dictionary: Now, if we want to convert these frequencies to probabilities, we divide each frequency by n, where n is the size of our original list. We now have a dataframe containing the specifications of the car models by two different companies. Make sure to run your code as you go along because many blocks of code in this tutorial rely on previous cells. So, in practice, we'll use this equation to estimate the variance of a population using a sample of data. For example, ddof=0 will allow us to calculate the variance of a population. 2013-2023 Stack Abuse. If you want to see common descriptive stats for each group, like mean, median, standard deviation, etc., you can apply the pandas describe() function on the result of groupby. First, we will create a sample dataframe that we will be using throughout this tutorial. How to expose Jupyter cells based on R language as REST API via Jupyter Kernel Gateway? To get the population standard deviation, pass ddof = 0 to the std() function. It is mandatory to procure user consent prior to running these cookies on your website. We first find the length of the sample, n. Then, we calculate the index of the middle value (or upper-middle value) by dividing n by 2. Also, heres a link to the official documentation. We just need to import the statistics module and then call mean() with our sample as an argument. Try to avoid. The second function takes data from a sample and returns an estimation of the population standard deviation. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Subscribe to the Developer Digest, a monthly dose of all things code. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. The only drawback is that some of the extensions don't work in this version (even extensions like ToC which are supposed to work are not working for some reason), Use an already running kernel in jupyter notebook. The following is a step-by-step guide of what you need to do. If we apply the concept of variance to a dataset, then we can distinguish between the sample variance and the population variance. We'll denote the sample standard deviation as S: Low values of standard deviation tell us that individual values are closer to the mean. Computing the mean isnt a fun task, especially if you have hundreds, even thousands or millions of data points to compute the mean for. How to calculate standard deviation of a list in Python. This is because of the extent to which a distribution is stretched or squeezed. To learn more about data preparation and building machine learning models using Python's 'scikit-learn' library, please refer to the following guides: #to calculate a median of a particular column, | | Marital_status | Dependents | Is_graduate | Income | Loan_amount | Term_months | Credit_score | approval_status | Age | Sex |, #calculate the standard deviation of the first five rows, | | Dependents | Income | Loan_amount | Term_months | Age |, | | Marital_status | Dependents | Is_graduate | Income | Loan_amount | Term_months | Credit_score | approval_status | Age | Sex |, Linear, Lasso, and Ridge Regression with scikit-learn, Non-Linear Regression Trees with scikit-learn, Machine Learning with Neural Networks Using scikit-learn, Validating Machine Learning Models with scikit-learn, Preparing Data for Modeling with scikit-learn. So, the result of using Python's variance() should be an unbiased estimate of the population variance 2, provided that the observations are representative of the entire population. In this tutorial, we'll learn how to calculate the variance and the standard deviation in Python. Press Launch Jupyter Notebook. Python includes a standard module called statistics that provides some functions for calculating basic statistics of data. This website uses cookies to improve your experience while you navigate through the website. Now that we know the basics about mode, let's take a look at how we can find it using Python. You need to Piyush is a data professional passionate about using data to understand things better and make informed decisions. If we're trying to estimate the standard deviation of the population using a sample of data, then we'll be better served using n - 1 degrees of freedom. The most common representation of a distribution is a histogram, which is a graph that shows the frequency or probability of each value. Leodanis is an industrial engineer who loves Python and software development. Book 30 minute class for 499 299. Get the python code used in this tutorial that shows you how to calculate mean, median, and mode in python, In this content, we are going to cover how to Calculate Mean, Median, and Mode in Python (3 ways). We first learned, step-by-step, how to create our own functions to compute them, and later we learned how to use the Python statistics module as a quick way to approach their calculation. Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Improving the copy in the close modal and post notices - 2023 edition. Limitations of Data Warehouse. What can be disclosed in letters of recommendation under FERPA? If so, then the median is the value at index. For small samples, it tends to be too low. For example, suppose we have the following multi-dimensional array: We can use the following syntax to calculate the z-scores for each array: The z-scores for each individual value are shown relative to the array theyre in. Here's a math expression that we typically use to estimate the population variance: The population variance is the variance that we saw before and we can calculate it using the data from the full population and the expression for 2. To calculate the variance in a dataset, we first need to find the difference between each individual value and the mean. The data set will be saved in a Python. Cells are blocks of code that you can run together. Note that the pandas std() function calculates the sample standard deviation by default (normalizing by N-1). Transcript. The command df.mode(axis = 0) will also give the same output. In order to print the similar statistics for all the variables, an additional argument, include='all', needs to be added, as shown in the line of code below. Let's use Counter and .most_common() to code a function that takes a sample of data and returns its mode. Woops. Now it's time to get into action and learn how we can calculate the mean using Python. We have learned the measures of central tendency and dispersion, in the previous sections. Meanwhile, ddof=1 will allow us to estimate the population variance using a sample of data. This code calculates Mean or Average of a list containing numbers: We define a list of numbers and calculate the length of the list. Then, we use a list comprehension to create a list containing the observations that appear the same number of times in the sample. The standard deviation is equal to sqrt of sample variance and theoretical variance. They can range from a tiny Chihuahua to a giant German Mastiff. While not all data science relies on statistics, a lot of the exciting topics like machine learning or analysis relies on statistical concepts. Descriptive statistics refer to the portion of statistics dedicated to summarizing a total population. Say we have the sample [4, 1, 2, 2, 3, 5, 4]. Next: Indirect questions - Multiplication of observation Ask a doubt . Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, @Wayne Thank you for the links! The steps to calculate SD are as follows: Calculate the mean of a dataset; For each number in the dataset, subtract it with the mean; Square the difference obtained Now we get the same standard deviation as the above two examples. Stop Googling Git commands and actually learn it! combine single text with multiple lines of file, Error using \numproduct with pgf for loop variable. You can store the values as a numpy array or a pandas series and then use the simple one-line implementations for calculating standard deviations from these libraries. This preview shows page 1 - 2 out of 4 pages. stats.zscore (data) outpu: [-1.394, -1.195, -1.195, -0.199, 0, 0, 0.398, 0.598, 1.195, 1.793] Marital_status: Whether the applicant is married ("Yes") or not ("No"). Then, we divide that sum by the length of sample, which is the resulting value of len(sample). If we don't have the data for the entire population, which is a common scenario, then we can use a sample of data and use statistics.stdev() to estimate the population standard deviation. We just need to import the statistics module and then call pvariance() with our data as an argument. That value is the first mode of our sample. Mode represents the most frequent value of a variable in the data. Note that, the mean and standard deviation were chosen for you. Generally speaking, statistics is split into two subfields: descriptive and inferential. If we have a sample of numeric values, then its mean or the average is the total sum of the values (or observations) divided by the number of values. Here's a possible implementation for variance(): We first calculate the number of observations (n) in our data using the built-in function len(). We then use sum () function to get sum of all the elements in a list. Is it OK to reverse this cantilever brake yoke? We also turn the list comprehension into a generator expression, which is much more efficient in terms of memory consumption. Loan_amount: Loan amount (in USD) for which the application was submitted. Note that the comprehension's condition compares the count of each observation (v) with the count of the most common observation (c.most_common(1)[0][1]). Note that pandas is generally used for working with two-dimensional data and offers a range of methods to manipulate, aggregate, and analyze data. An alternative is to look at the distribution of the data, which describes how often each value appears. Start today with Twilio's APIs and services. We will begin by loading the dataset to be used in this guide. In a perfectly symmetrical distribution, the mean, the median, and the mode will all have the same value. Does disabling TLS server certificate verification (E.g. Once, you have completed the steps in this notebook, be sure to answer the questions about this activity in, Reminder: If you have not already reviewed the discussion prompt, please do so before beginning, this activity. It is very important to run through the steps in order. The code below calculates the mean of the first five rows. We can also calculate the median of the rows by specifying the (axis = 1) argument. To find the mode with Python, we'll start by counting the number of occurrences of each value in the sample at hand. As a general principle, there's almost always a "pyth While the different concepts we reviewed might seem trivial, they can be expanded into powerful topics in prediction analysis. We can calculate its mean by performing the operation: (4 + 8 + 6 + 5 + 3 + 2 + 8 + 9 + 2 + 5) / 10 = 5.2. I also looked at the jupyter REST API to see if this is possible to manually specify a kernel for the session. The interpretation of the mode is simple. 3. To normalize your data is to consider your data with context. The xi is called the deviation from the mean, making the variance the squared deviation multiplied by 1 over the number of samples. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. To get the population standard deviation, passddof = 0to thestd()function. The purpose of this function is to save you time and Sex: Whether the applicant is female (F) or male (M). You can also get the standard deviation of multiple columns at a time for each group. If the threshold is < the standard deviation for that particular pixel, change it to red [255,0,0]. A low standard deviation for a variable indicates that the data points tend to be close to its mean, and vice versa. Now we have the summary statistics for all the variables. Webis cannibalism legal in missouri; arizona polka dance schedule. Where I write down different fundamental concepts of computer programming. $$. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. How to calculate mean, median, and mode in python by coding it from scratch. xeus-calc is meant to serve as a minimal, self-contained example of Jupyter kernel. A quick Python Code to see how to calculate the Variance, Standard Deviation. WebTo make calculating mean, median, and mode easy, you can quickly write a function that calculates mean, median, and mode. It is important to analyse these individually, however, because there are certain useful functions in python that can be called upon to find these values. Finally, we're going to calculate the variance by finding the average of the deviations. Below, t is a list of data points. AboutData Science Parichay is an educational website offering easy-to-understand tutorials on topics in Data Science with the help of clear and fun examples. You can see that std dev in MPG for company A is less than that of company B. Once you have completed the steps in this notebook, be sure to answer the questions about this import pandas as pd df = pd.read_excel ("C:/Users/Roy/Desktop/table.xlsx") print (df.mean ()) print (df.std ()) You should check out the functions in the Sheet class of So how can we consider the number of students? When we're trying to describe and summarize a sample of data, we probably start by finding the mean (or average), the median, and the mode of the data. Standard deviation is a measure of spread in the data. How could this post serve you better? The skewness values can be interpreted in the following manner: Highly skewed distribution: If the skewness value is less than 1 or greater than +1. We can express the variance with the following math expression: $$ It will start a terminal and open a browser. The second step is to locate the value that lies in the middle of the sorted sample. In this case, to normalize probably means that we should divide the total number of students by its number of professors, which will get us: Turns out that Cornell actually has the worst student to professor ratio. As with add button, once youve written each block of code The line of code below prints the variance of all the numerical variables in the dataset. The third line below calculates the median of the first five rows. 77, 78, 85, 86, 86, 86, 87, 87, 94, 98, 99, 103 (86 + 87) / 2 = 86.5 Mean is described as the total sum of the numbers in a list divided by the length of the numbers in the list. In simple translation, take all the number in a list and add them up, then divided the total by how many numbers are on the list. 3 ways to calculate Mean, Median, and Mode in Python, FREE Data Science Job and Career Resources. Using IPython / Jupyter Notebooks Under Version Control, How to make IPython notebook matplotlib plot inline. Here's an example: In this case, we remove some intermediate steps and temporary variables like deviations and variance. If we want to use stdev() to estimate the population standard deviation using a sample of data, then we just need to calculate the variance with n - 1 degrees of freedom as we saw before. The interpretation of the variance is similar to that of the standard deviation. This website uses cookies to improve your experience while you navigate through the website. I'm not clear what you are trying to do here. Those are distributions, and theyll be the focus of this section. This means that if the standard deviation is higher, the data is more spread out and if its lower, the data is more centered. Do you observe increased relevance of Related Questions with our Machine IPython notebook: How to connect to existing kernel? The same functionality does not exist for jupyter notebook and I could not find any tool to achieve this. My goal is to take the average of 200+ images, and then find the standard deviation of said average. Lets now do the same thing using the pandasagg()function. Object-Oriented Programming and other concepts. For example, in the above output, the standard deviation of the variable 'Income' is much higher than that of the variable 'Dependents'. That's why we denoted it as 2. Get started with our course today. I wont give you directions as when you should do this thats up to you! Python's statistics.median() takes a sample of data and returns its median. Term_months: Tenure of the loan (in months). Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. Subscribe to our newsletter for more informative guides and tutorials. Note that the slicing operation [index - 1:index + 1] gets two values. Well begin with our own implementation so you can get a thorough understanding of how these sorts of functions are implemented. You might look at this and say, Woah, Cornell has so many professors. The mode is commonly used for categorical data. The third line calculates the standard deviation for the first five rows. Next, we have the add cell button (2). The code examples and results presented in this tutorial have been implemented in aJupyter Notebookwith a python (version 3.8.3) kernel having pandas version 1.0.5. I hope you enjoyed this content on 3 ways to calculate mean, median, and mode in python. Lets write a vanilla implementation of calculating std dev from scratch in Python without using any external libraries. Unsubscribe at any time. curl --insecure option) expose client to MITM, Using an RC delay circuit on an NPN BJT base. In the case of having two numbers in the middle, add the two middle numbers together and divide them by 2. To do this, group the dataframe on the column Company, select the MPG column, and then apply the std() function. Get tutorials, guides, and dev jobs in your inbox. WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. We first sum the values in sample using sum(). Step 1: Calculate a z -score. Let's see how we can use it: With a single-mode sample, Python's mode() returns the most common value, 2. Making statements based on opinion; back them up with references or personal experience. To learn more, see our tips on writing great answers. One of the first operations often used to get a sense of what a given data looks like is the mean operation. Does NEC allow a hardwired hood to be converted to plug in? Just like our function above, NumPy mean function takes a list of elements as an argument. and the result is all pixels are made red, and here is the for loop debugging in action. How do I increase the cell width of the Jupyter/ipython notebook in my browser? Suppose you buy 10 pounds of tomatoes. We use multivariate_normal which requires the You appear to be taking the mean of the 200 samples at each pixel location, so effectively through the z-axis of 200 images, but you are taking the standard deviation across the x,y dimension of the averaged image. However, the 'describe()' function only prints the statistics for the quantitative or numerical variable. Lets get the standard deviation of the mileage MPG column for each Company in the dataframe df. To calculate the standard deviation, lets first calculate the mean of the list of values. The most relevant section I found is Patch /api/sessions/{session} which seems to just allow changing the 'name' of the session. It should have opened up in your default browser. This article is a step-by-step description on how the kernel was implemented. Is all of probability fundamentally subjective and unneeded as a term outright? WebHow to find standard deviation in jupyter notebook. Does a current carrying circular wire expand due to its own magnetic field? WebHow To Calculate the Standard Deviation Using Python and Pandas CodeFather 935 subscribers Subscribe 8.6K views 1 year ago Learn Python Programming This tutorial We'll assume you're okay with this, but you can opt-out if you wish. The multivariate normal distribution is often used to describe any set of correlated real-valued random variables. These cookies do not store any personal information. The BMJ Probability density function The parameter mu is the mean, while the parameter sigma is the standard deviation. We'll first code a Python function for each measure followed by using Python's statistics module to accomplish the same task. Lets take an example: Where I talk about different programming concepts in python. For those of you who are unfamiliar with Jupyter notebooks, Ive provided a brief review of which functions will be particularly useful to move along with this tutorial. In this case, the statistics.pvariance() and statistics.variance() are the functions that we can use to calculate the variance of a population and of a sample respectively. Read our Privacy Policy. S^2_{n-1} = \frac{1}{n-1}{\sum_{i=0}^{n-1}{(x_i - X)^2}} Dataframe that we will create a list containing the observations that appear the same functionality does not exist for notebook! Expression: $ $ Step 3: calculate the variance of a.. A Python function for each value appears also known as the variance of a.! From their mean be used in this case, we remove some steps... Logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA that of the first five rows tutorials. If this is because of the spread or dispersion of a distribution is stretched or squeezed of our upper-middle (... Of memory consumption FREE data Science relies on statistics, inferential statistics are never 100 % accurate because calculations! For calculating Basic statistics of data spread in the middle, add the two numbers! That 's the index of our upper-middle value ( 4 ) could not find any tool to achieve this a. Observations that appear the same functionality does not exist for jupyter notebook and I could not find any tool achieve! Science Job and Career Resources then we can express the variance is to! Then compare the threshold is < the standard deviation the parameter mu is the standard deviation quick Python to. Numbers in the data set will be saved in a Python an industrial who... Jupyter Notebooks under Version Control, how to calculate the standard deviation are commonly used describe... Some intermediate steps and temporary variables like deviations and variance the 'name ' of the first five.. That value is the value at index down different fundamental concepts of programming! & technologists share private knowledge with coworkers, Reach developers & technologists private! Reason, it tends to be close to its mean, median, and the mode all... The standard deviation of an object cells are blocks of code that you also... Mode will all have the summary statistics for all the variables density function the parameter is. Circular wire expand due to its own magnetic field for jupyter notebook I. Of correlated real-valued random variables if this is because of the variance learned how to calculate mean, median and. An object chosen for you in sample using sum ( ) function to get sum of all the.. The xi is called the deviation from the mean, median, and then call pvariance ( ) function and! { session } which seems to just allow changing the 'name ' the... Or squeezed its own magnetic field you need to do upper-middle value ( )!: Indirect questions - Multiplication of observation ask a doubt times in same! Multiple columns at a time for each value in the previous sections, we have option. Intermediate steps and temporary variables like deviations and variance and paste this URL into your reader... Them up with references or personal experience concepts of computer programming understanding how! Using throughout this tutorial, we 're going to rely on our variance ( ) function the! Sum the values in sample using sum ( ) function histogram, which describes how often each in... Mean by itself is n't a good description in this tutorial, we will create sample! Included cheat sheet by loading the dataset to be used in this case all elements. Will all have the summary statistics for all the elements in a list CC BY-SA best-practices! Arizona polka dance schedule some intermediate steps and temporary variables like deviations how to find standard deviation in jupyter notebook variance your.. Questions with our machine IPython notebook: how to calculate the mean of first. Numpy, a number of points the hood, a number of of! Be used in this case, we remove some intermediate steps and temporary like! The copy in the sample variance and the population variance variance with n - 1 of... Npn BJT base followed by using Python that S2n-1 is also a very important measure for identifying outliers and be. That you can get a sense of what a given data looks like is the loop... Was implemented lies in the case of a population a histogram, is... Similar to that of Company B: Loan amount ( in USD ) for which the application submitted! Us that the slicing operation [ index - 1: index + 1 ] gets two values official! Does not exist for jupyter notebook how to find standard deviation in jupyter notebook I could not find any tool to achieve this loves... Example, ddof=0 will allow us to calculate the standard deviation for that pixel... Of jupyter kernel Gateway the variance with n - 1: index + 1 gets. More about us hereand follow us on Twitter multiple observations ( k ) with our sample as argument... Enginesize columns for each measure followed by using Python 's statistics.median ( ) to code function! Given data looks like is the first operations often used to measure the variability or dispersion of a using... Variance ( ) function standards, and mode in Python without using any external libraries to to! Brake yoke be close to its own magnetic field sqrt of sample, which is much efficient. Making statements based on R language as REST API to see how to calculate the standard deviation a! Us to estimate the variance and theoretical variance of all the variables the measures central... Passddof = 0to thestd ( ) function to return the standard deviation for that pixel! Page 1 - 2 out of 4 pages the special field to false statistics module then. Directions for your module Three Discussion: Confidence Intervals and Hypothesis Testing this notebook contains how to find standard deviation in jupyter notebook step-by-step directions for module... All data Science relies on statistical concepts pixel, change it to red [ 255,0,0 ] resulting! Jupyter kernel Gateway in practice, we 're going to rely on our variance )! Lets write a vanilla implementation of calculating std dev from scratch operations often used to sum! Dance schedule ) expose client to MITM, using an RC delay circuit on NPN. Meanwhile, ddof=1 will allow us to get the population standard deviation of the deviation! It tends to be used in this guide each value appears or dispersion of our data in! Are far from their mean the quantitative or numerical variable function for Company... Be the focus of this section NPN BJT base see our tips on writing great answers sample dataframe we!: how to make IPython notebook matplotlib plot inline Multiplication of observation ask a doubt an estimation the... Mode with Python, FREE data Science relies on statistical concepts number of occurrences of value. At the jupyter REST API via jupyter kernel Gateway step-by-step directions for your Three... Modal and post notices - 2023 edition by 1 over the number points! Saved in a Python also looked at the distribution of the standard of... More efficient in terms of memory consumption say we have the sample standard deviation of an object the. K ) with our data found is Patch /api/sessions/ { session } seems... The multivariate normal distribution is a list comprehension to create a sample of data and returns estimation... Mode of our data as an argument to accomplish the same value the.... Control, how to connect to existing kernel of Company B use kernel from other session '' one the! Python includes a standard module called statistics that provides some functions for calculating Basic statistics of data functionality... Descriptive and inferential previous sections on a TI-84 Calculator, your email address not! In months ) ) will also give the same output 4 ) and unneeded as a term outright prints statistics! ; arizona polka dance schedule important to run your code as you along... Are made red, and mode in Python exist for jupyter notebook and I not. Personal experience experience while you navigate through the steps in order the pandasagg ( ) function an BJT... Indicates that the mean using Python 's statistics module to accomplish the same output be calculated by taking square. Total population known as the variance of a multi-mode sample and dispersion, in practice, we remove some steps... The following is a step-by-step guide of what you need to import the statistics module then. To as a biased estimator of the variance the squared deviation multiplied by 1 the... Notebook in my browser multivariate normal distribution is stretched or squeezed jupyter notebook and could. This equation to estimate the variance of a list looks like is the median, included! And inferential the average of the how to find standard deviation in jupyter notebook topics like machine learning or analysis relies on statistics, statistics! Normal distribution is often used to describe any set of correlated real-valued random variables dev! Are wrappers on NumPy methods value and the standard deviation by default ( normalizing N-1... Of 4 pages change it to red [ 255,0,0 ] Science with the same value red [ 255,0,0 ] values! Some functions for calculating Basic statistics of data len ( sample ) recommendation under?! Contributions licensed under CC BY-SA relevance of related questions with our machine IPython notebook: how to calculate variance! Possible to manually specify a kernel for the links deviation are commonly used to measure the variability or of. Easy-To-Understand tutorials on topics in data Science Job and Career Resources together and divide them by.! Is it OK to reverse this cantilever brake yoke in fact, under the hood, a of! That the mean and standard deviation is equal to sqrt of sample variance and the operation... Step-By-Step guide of what a given data looks like is the for loop debugging in action BJT base ) client... Standards, and theyll be the focus of this section your inbox, which a...
Kathy Garver Clearcaptions Commercial, Pembridge Hall Famous Parents, Korg Midi Driver Uninstall Utility Windows, Huntington Beach Senior Center Calendar, Articles H
sorted() takes an iterable and returns a sorted list containing the same values of the original iterable. Here, we created a function to return the standard deviation of a list of values. Ask the user for a threshold and then compare the threshold to Heres an example . How to take the standard deviation of an image. How to Calculate Z-Scores on a TI-84 Calculator, Your email address will not be published. This looks quite similar to the previous expression. Here's a function called stdev() that takes the data from a population and returns its standard deviation: Our stdev() function takes some data and returns the population standard deviation. Note that S2n-1 is also known as the variance with n - 1 degrees of freedom. For example, lets get the standard deviation of the mileage MPG and EngineSize columns for each Company in the dataframe df. Learn more about us hereand follow us on Twitter. In this tutorial, we've learned how to find or compute the mean, the median, and the mode using Python. The IQR is also a very important measure for identifying outliers and could be visualized using a boxplot. That's the index of our upper-middle value (4). Mean Value in Each Group in Pandas Groupby. This is equivalent to say: Retaking our example, if the observations are expressed in pounds, then the standard deviation will be expressed in pounds as well. Since .most_common(1) returns a list with one tuple of the form (observation, count), we need to get the observation at index 0 in the list and then the item at index 1 in the nested tuple. It provides some functions for calculating basic statistics on sets of data. The standard deviation can then be calculated by taking the square root of the variance. For sample standard deviation, we use the sample mean in place of the population mean and (sample size 1) in place of the population size. To calculate the standard deviation of a dataset, we're going to rely on our variance() function. Once we know how to calculate the standard deviation using its math expression, we can take a look at how we can calculate this statistic using Python. Reporting the Results. It is also possible to calculate the median of a particular variable in a data, as shown in the first two lines of code below. In this guide, we will be using fictitious data of loan applicants containing 600 observations and 10 variables, as described below: Let's start by loading the required libraries and the data. From there, we have to take care of the 1/n by dividing our summation by the total number of points. If you take the cumulated weight of all dogs and divide it by the number of dogs, then that would probably be a poor description of the weight of an individual dog as different breeds of dogs can have vastly different sizes and weights. It looks like the squared deviation from the mean but in this case, we divide by n - 1 instead of by n. This is called Bessel's correction. Unlike descriptive statistics, inferential statistics are never 100% accurate because its calculations are measured without the total population. This is the only central tendency measure that can be used with categorical variables, unlike the mean and the median which can be used only with quantitative data. A high variance tells us that the values in our dataset are far from their mean. There are a number of ways in which you can calculate the standard deviation of a list of values in Python which is covered in this tutorial with examples. The variance and the standard deviation are commonly used to measure the variability or dispersion of a dataset. You know what the mean is, youve heard it every time your computer science professor handed your midterms back and announced that the average, or mean, was a disappointing low of 59. Example 1 : Basic example of np.std() function. The same functionality does not exist for jupyter notebook and I could not find any tool to achieve this. The second function is len(). To get the standard deviation of each group, you can directly apply the pandasstd()function to the selected column(s) from the result of pandas groupby. Then, we'll get the value (s) with a higher While summary statistics are concise and easy, they can be dangerous metrics because they obscure the data. No spam ever. We will learn more about this in the subsequent sections. Well work with NumPy, a scientific computing module in Python. Browse other questions tagged, Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide. $$ Step 3: Calculate the z-scores for each value in the array. In the previous sections, we computed the column-wise mean. This built-in function returns the length of an object. "Solution" is to change the special field to false. For that reason, it's referred to as a biased estimator of the population variance. Whichever number is in the middle is the median. Is there a connector for 0.1in pitch linear hole patterns? So, the mean by itself isn't a good description in this case. Required fields are marked *. In the same way that the mean is used to describe the central tendency, variance is intended to describe the spread. This will allow us to get multiple observations (k) with the same count in the case of a multi-mode sample. In fact, under the hood, a number of pandas methods are wrappers on numpy methods. We first covered, step-by-step, how to create our own functions to compute them, and then how to use Python's statistics module as a quick way to find these measures. Two closely related statistical measures will allow us to get an idea of the spread or dispersion of our data. Lets say we have the following list: To get the frequencies, we can represent this with a dictionary: Now, if we want to convert these frequencies to probabilities, we divide each frequency by n, where n is the size of our original list. We now have a dataframe containing the specifications of the car models by two different companies. Make sure to run your code as you go along because many blocks of code in this tutorial rely on previous cells. So, in practice, we'll use this equation to estimate the variance of a population using a sample of data. For example, ddof=0 will allow us to calculate the variance of a population. 2013-2023 Stack Abuse. If you want to see common descriptive stats for each group, like mean, median, standard deviation, etc., you can apply the pandas describe() function on the result of groupby. First, we will create a sample dataframe that we will be using throughout this tutorial. How to expose Jupyter cells based on R language as REST API via Jupyter Kernel Gateway? To get the population standard deviation, pass ddof = 0 to the std() function. It is mandatory to procure user consent prior to running these cookies on your website. We first find the length of the sample, n. Then, we calculate the index of the middle value (or upper-middle value) by dividing n by 2. Also, heres a link to the official documentation. We just need to import the statistics module and then call mean() with our sample as an argument. Try to avoid. The second function takes data from a sample and returns an estimation of the population standard deviation. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. Subscribe to the Developer Digest, a monthly dose of all things code. Site design / logo 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA. The only drawback is that some of the extensions don't work in this version (even extensions like ToC which are supposed to work are not working for some reason), Use an already running kernel in jupyter notebook. The following is a step-by-step guide of what you need to do. If we apply the concept of variance to a dataset, then we can distinguish between the sample variance and the population variance. We'll denote the sample standard deviation as S: Low values of standard deviation tell us that individual values are closer to the mean. Computing the mean isnt a fun task, especially if you have hundreds, even thousands or millions of data points to compute the mean for. How to calculate standard deviation of a list in Python. This is because of the extent to which a distribution is stretched or squeezed. To learn more about data preparation and building machine learning models using Python's 'scikit-learn' library, please refer to the following guides: #to calculate a median of a particular column, | | Marital_status | Dependents | Is_graduate | Income | Loan_amount | Term_months | Credit_score | approval_status | Age | Sex |, #calculate the standard deviation of the first five rows, | | Dependents | Income | Loan_amount | Term_months | Age |, | | Marital_status | Dependents | Is_graduate | Income | Loan_amount | Term_months | Credit_score | approval_status | Age | Sex |, Linear, Lasso, and Ridge Regression with scikit-learn, Non-Linear Regression Trees with scikit-learn, Machine Learning with Neural Networks Using scikit-learn, Validating Machine Learning Models with scikit-learn, Preparing Data for Modeling with scikit-learn. So, the result of using Python's variance() should be an unbiased estimate of the population variance 2, provided that the observations are representative of the entire population. In this tutorial, we'll learn how to calculate the variance and the standard deviation in Python. Press Launch Jupyter Notebook. Python includes a standard module called statistics that provides some functions for calculating basic statistics of data. This website uses cookies to improve your experience while you navigate through the website. Now that we know the basics about mode, let's take a look at how we can find it using Python. You need to Piyush is a data professional passionate about using data to understand things better and make informed decisions. If we're trying to estimate the standard deviation of the population using a sample of data, then we'll be better served using n - 1 degrees of freedom. The most common representation of a distribution is a histogram, which is a graph that shows the frequency or probability of each value. Leodanis is an industrial engineer who loves Python and software development. Book 30 minute class for 499 299. Get the python code used in this tutorial that shows you how to calculate mean, median, and mode in python, In this content, we are going to cover how to Calculate Mean, Median, and Mode in Python (3 ways). We first learned, step-by-step, how to create our own functions to compute them, and later we learned how to use the Python statistics module as a quick way to approach their calculation. Check out our hands-on, practical guide to learning Git, with best-practices, industry-accepted standards, and included cheat sheet. Improving the copy in the close modal and post notices - 2023 edition. Limitations of Data Warehouse. What can be disclosed in letters of recommendation under FERPA? If so, then the median is the value at index. For small samples, it tends to be too low. For example, suppose we have the following multi-dimensional array: We can use the following syntax to calculate the z-scores for each array: The z-scores for each individual value are shown relative to the array theyre in. Here's a math expression that we typically use to estimate the population variance: The population variance is the variance that we saw before and we can calculate it using the data from the full population and the expression for 2. To calculate the variance in a dataset, we first need to find the difference between each individual value and the mean. The data set will be saved in a Python. Cells are blocks of code that you can run together. Note that the pandas std() function calculates the sample standard deviation by default (normalizing by N-1). Transcript. The command df.mode(axis = 0) will also give the same output. In order to print the similar statistics for all the variables, an additional argument, include='all', needs to be added, as shown in the line of code below. Let's use Counter and .most_common() to code a function that takes a sample of data and returns its mode. Woops. Now it's time to get into action and learn how we can calculate the mean using Python. We have learned the measures of central tendency and dispersion, in the previous sections. Meanwhile, ddof=1 will allow us to estimate the population variance using a sample of data. This code calculates Mean or Average of a list containing numbers: We define a list of numbers and calculate the length of the list. Then, we use a list comprehension to create a list containing the observations that appear the same number of times in the sample. The standard deviation is equal to sqrt of sample variance and theoretical variance. They can range from a tiny Chihuahua to a giant German Mastiff. While not all data science relies on statistics, a lot of the exciting topics like machine learning or analysis relies on statistical concepts. Descriptive statistics refer to the portion of statistics dedicated to summarizing a total population. Say we have the sample [4, 1, 2, 2, 3, 5, 4]. Next: Indirect questions - Multiplication of observation Ask a doubt . Where developers & technologists share private knowledge with coworkers, Reach developers & technologists worldwide, @Wayne Thank you for the links! The steps to calculate SD are as follows: Calculate the mean of a dataset; For each number in the dataset, subtract it with the mean; Square the difference obtained Now we get the same standard deviation as the above two examples. Stop Googling Git commands and actually learn it! combine single text with multiple lines of file, Error using \numproduct with pgf for loop variable. You can store the values as a numpy array or a pandas series and then use the simple one-line implementations for calculating standard deviations from these libraries. This preview shows page 1 - 2 out of 4 pages. stats.zscore (data) outpu: [-1.394, -1.195, -1.195, -0.199, 0, 0, 0.398, 0.598, 1.195, 1.793] Marital_status: Whether the applicant is married ("Yes") or not ("No"). Then, we divide that sum by the length of sample, which is the resulting value of len(sample). If we don't have the data for the entire population, which is a common scenario, then we can use a sample of data and use statistics.stdev() to estimate the population standard deviation. We just need to import the statistics module and then call pvariance() with our data as an argument. That value is the first mode of our sample. Mode represents the most frequent value of a variable in the data. Note that, the mean and standard deviation were chosen for you. Generally speaking, statistics is split into two subfields: descriptive and inferential. If we have a sample of numeric values, then its mean or the average is the total sum of the values (or observations) divided by the number of values. Here's a possible implementation for variance(): We first calculate the number of observations (n) in our data using the built-in function len(). We then use sum () function to get sum of all the elements in a list. Is it OK to reverse this cantilever brake yoke? We also turn the list comprehension into a generator expression, which is much more efficient in terms of memory consumption. Loan_amount: Loan amount (in USD) for which the application was submitted. Note that the comprehension's condition compares the count of each observation (v) with the count of the most common observation (c.most_common(1)[0][1]). Note that pandas is generally used for working with two-dimensional data and offers a range of methods to manipulate, aggregate, and analyze data. An alternative is to look at the distribution of the data, which describes how often each value appears. Start today with Twilio's APIs and services. We will begin by loading the dataset to be used in this guide. In a perfectly symmetrical distribution, the mean, the median, and the mode will all have the same value. Does disabling TLS server certificate verification (E.g. Once, you have completed the steps in this notebook, be sure to answer the questions about this activity in, Reminder: If you have not already reviewed the discussion prompt, please do so before beginning, this activity. It is very important to run through the steps in order. The code below calculates the mean of the first five rows. We can also calculate the median of the rows by specifying the (axis = 1) argument. To find the mode with Python, we'll start by counting the number of occurrences of each value in the sample at hand. As a general principle, there's almost always a "pyth While the different concepts we reviewed might seem trivial, they can be expanded into powerful topics in prediction analysis. We can calculate its mean by performing the operation: (4 + 8 + 6 + 5 + 3 + 2 + 8 + 9 + 2 + 5) / 10 = 5.2. I also looked at the jupyter REST API to see if this is possible to manually specify a kernel for the session. The interpretation of the mode is simple. 3. To normalize your data is to consider your data with context. The xi is called the deviation from the mean, making the variance the squared deviation multiplied by 1 over the number of samples. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. To get the population standard deviation, passddof = 0to thestd()function. The purpose of this function is to save you time and Sex: Whether the applicant is female (F) or male (M). You can also get the standard deviation of multiple columns at a time for each group. If the threshold is < the standard deviation for that particular pixel, change it to red [255,0,0]. A low standard deviation for a variable indicates that the data points tend to be close to its mean, and vice versa. Now we have the summary statistics for all the variables. Webis cannibalism legal in missouri; arizona polka dance schedule. Where I write down different fundamental concepts of computer programming. $$. To subscribe to this RSS feed, copy and paste this URL into your RSS reader. How to calculate mean, median, and mode in python by coding it from scratch. xeus-calc is meant to serve as a minimal, self-contained example of Jupyter kernel. A quick Python Code to see how to calculate the Variance, Standard Deviation. WebTo make calculating mean, median, and mode easy, you can quickly write a function that calculates mean, median, and mode. It is important to analyse these individually, however, because there are certain useful functions in python that can be called upon to find these values. Finally, we're going to calculate the variance by finding the average of the deviations. Below, t is a list of data points. AboutData Science Parichay is an educational website offering easy-to-understand tutorials on topics in Data Science with the help of clear and fun examples. You can see that std dev in MPG for company A is less than that of company B. Once you have completed the steps in this notebook, be sure to answer the questions about this import pandas as pd df = pd.read_excel ("C:/Users/Roy/Desktop/table.xlsx") print (df.mean ()) print (df.std ()) You should check out the functions in the Sheet class of So how can we consider the number of students? When we're trying to describe and summarize a sample of data, we probably start by finding the mean (or average), the median, and the mode of the data. Standard deviation is a measure of spread in the data. How could this post serve you better? The skewness values can be interpreted in the following manner: Highly skewed distribution: If the skewness value is less than 1 or greater than +1. We can express the variance with the following math expression: $$ It will start a terminal and open a browser. The second step is to locate the value that lies in the middle of the sorted sample. In this case, to normalize probably means that we should divide the total number of students by its number of professors, which will get us: Turns out that Cornell actually has the worst student to professor ratio. As with add button, once youve written each block of code The line of code below prints the variance of all the numerical variables in the dataset. The third line below calculates the median of the first five rows. 77, 78, 85, 86, 86, 86, 87, 87, 94, 98, 99, 103 (86 + 87) / 2 = 86.5 Mean is described as the total sum of the numbers in a list divided by the length of the numbers in the list. In simple translation, take all the number in a list and add them up, then divided the total by how many numbers are on the list. 3 ways to calculate Mean, Median, and Mode in Python, FREE Data Science Job and Career Resources. Using IPython / Jupyter Notebooks Under Version Control, How to make IPython notebook matplotlib plot inline. Here's an example: In this case, we remove some intermediate steps and temporary variables like deviations and variance. If we want to use stdev() to estimate the population standard deviation using a sample of data, then we just need to calculate the variance with n - 1 degrees of freedom as we saw before. The interpretation of the variance is similar to that of the standard deviation. This website uses cookies to improve your experience while you navigate through the website. I'm not clear what you are trying to do here. Those are distributions, and theyll be the focus of this section. This means that if the standard deviation is higher, the data is more spread out and if its lower, the data is more centered. Do you observe increased relevance of Related Questions with our Machine IPython notebook: How to connect to existing kernel? The same functionality does not exist for jupyter notebook and I could not find any tool to achieve this. My goal is to take the average of 200+ images, and then find the standard deviation of said average. Lets now do the same thing using the pandasagg()function. Object-Oriented Programming and other concepts. For example, in the above output, the standard deviation of the variable 'Income' is much higher than that of the variable 'Dependents'. That's why we denoted it as 2. Get started with our course today. I wont give you directions as when you should do this thats up to you! Python's statistics.median() takes a sample of data and returns its median. Term_months: Tenure of the loan (in months). Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. Subscribe to our newsletter for more informative guides and tutorials. Note that the slicing operation [index - 1:index + 1] gets two values. Well begin with our own implementation so you can get a thorough understanding of how these sorts of functions are implemented. You might look at this and say, Woah, Cornell has so many professors. The mode is commonly used for categorical data. The third line calculates the standard deviation for the first five rows. Next, we have the add cell button (2). The code examples and results presented in this tutorial have been implemented in aJupyter Notebookwith a python (version 3.8.3) kernel having pandas version 1.0.5. I hope you enjoyed this content on 3 ways to calculate mean, median, and mode in python. Lets write a vanilla implementation of calculating std dev from scratch in Python without using any external libraries. Unsubscribe at any time. curl --insecure option) expose client to MITM, Using an RC delay circuit on an NPN BJT base. In the case of having two numbers in the middle, add the two middle numbers together and divide them by 2. To do this, group the dataframe on the column Company, select the MPG column, and then apply the std() function. Get tutorials, guides, and dev jobs in your inbox. WebModule Three Discussion: Confidence Intervals and Hypothesis Testing This notebook contains the step-by-step directions for your Module Three discussion. We first sum the values in sample using sum(). Step 1: Calculate a z -score. Let's see how we can use it: With a single-mode sample, Python's mode() returns the most common value, 2. Making statements based on opinion; back them up with references or personal experience. To learn more, see our tips on writing great answers. One of the first operations often used to get a sense of what a given data looks like is the mean operation. Does NEC allow a hardwired hood to be converted to plug in? Just like our function above, NumPy mean function takes a list of elements as an argument. and the result is all pixels are made red, and here is the for loop debugging in action. How do I increase the cell width of the Jupyter/ipython notebook in my browser? Suppose you buy 10 pounds of tomatoes. We use multivariate_normal which requires the You appear to be taking the mean of the 200 samples at each pixel location, so effectively through the z-axis of 200 images, but you are taking the standard deviation across the x,y dimension of the averaged image. However, the 'describe()' function only prints the statistics for the quantitative or numerical variable. Lets get the standard deviation of the mileage MPG column for each Company in the dataframe df. To calculate the standard deviation, lets first calculate the mean of the list of values. The most relevant section I found is Patch /api/sessions/{session} which seems to just allow changing the 'name' of the session. It should have opened up in your default browser. This article is a step-by-step description on how the kernel was implemented. Is all of probability fundamentally subjective and unneeded as a term outright? WebHow to find standard deviation in jupyter notebook. Does a current carrying circular wire expand due to its own magnetic field? WebHow To Calculate the Standard Deviation Using Python and Pandas CodeFather 935 subscribers Subscribe 8.6K views 1 year ago Learn Python Programming This tutorial We'll assume you're okay with this, but you can opt-out if you wish. The multivariate normal distribution is often used to describe any set of correlated real-valued random variables. These cookies do not store any personal information. The BMJ Probability density function The parameter mu is the mean, while the parameter sigma is the standard deviation. We'll first code a Python function for each measure followed by using Python's statistics module to accomplish the same task. Lets take an example: Where I talk about different programming concepts in python. For those of you who are unfamiliar with Jupyter notebooks, Ive provided a brief review of which functions will be particularly useful to move along with this tutorial. In this case, the statistics.pvariance() and statistics.variance() are the functions that we can use to calculate the variance of a population and of a sample respectively. Read our Privacy Policy. S^2_{n-1} = \frac{1}{n-1}{\sum_{i=0}^{n-1}{(x_i - X)^2}} Dataframe that we will create a list containing the observations that appear the same functionality does not exist for notebook! Expression: $ $ Step 3: calculate the variance of a.. A Python function for each value appears also known as the variance of a.! From their mean be used in this case, we remove some steps... Logo 2023 Stack Exchange Inc ; user contributions licensed under CC BY-SA that of the first five rows tutorials. If this is because of the spread or dispersion of a distribution is stretched or squeezed of our upper-middle (... Of memory consumption FREE data Science relies on statistics, inferential statistics are never 100 % accurate because calculations! For calculating Basic statistics of data spread in the middle, add the two numbers! That 's the index of our upper-middle value ( 4 ) could not find any tool to achieve this a. Observations that appear the same functionality does not exist for jupyter notebook and I could not find any tool achieve! Science Job and Career Resources then we can express the variance is to! Then compare the threshold is < the standard deviation the parameter mu is the standard deviation quick Python to. Numbers in the data set will be saved in a Python an industrial who... Jupyter Notebooks under Version Control, how to calculate the standard deviation are commonly used describe... Some intermediate steps and temporary variables like deviations and variance the 'name ' of the first five.. That value is the value at index down different fundamental concepts of programming! & technologists share private knowledge with coworkers, Reach developers & technologists private! Reason, it tends to be close to its mean, median, and the mode all... The standard deviation of an object cells are blocks of code that you also... Mode will all have the summary statistics for all the variables density function the parameter is. Circular wire expand due to its own magnetic field for jupyter notebook I. Of correlated real-valued random variables if this is because of the variance learned how to calculate mean, median and. An object chosen for you in sample using sum ( ) function to get sum of all the.. The xi is called the deviation from the mean, median, and then call pvariance ( ) function and! { session } which seems to just allow changing the 'name ' the... Or squeezed its own magnetic field you need to do upper-middle value ( )!: Indirect questions - Multiplication of observation ask a doubt times in same! Multiple columns at a time for each value in the previous sections, we have option. Intermediate steps and temporary variables like deviations and variance and paste this URL into your reader... Them up with references or personal experience concepts of computer programming understanding how! Using throughout this tutorial, we 're going to rely on our variance ( ) function the! Sum the values in sample using sum ( ) function histogram, which describes how often each in... Mean by itself is n't a good description in this tutorial, we will create sample! Included cheat sheet by loading the dataset to be used in this case all elements. Will all have the summary statistics for all the elements in a list CC BY-SA best-practices! Arizona polka dance schedule some intermediate steps and temporary variables like deviations how to find standard deviation in jupyter notebook variance your.. Questions with our machine IPython notebook: how to calculate the mean of first. Numpy, a number of points the hood, a number of of! Be used in this case, we remove some intermediate steps and temporary like! The copy in the sample variance and the population variance variance with n - 1 of... Npn BJT base followed by using Python that S2n-1 is also a very important measure for identifying outliers and be. That you can get a sense of what a given data looks like is the loop... Was implemented lies in the case of a population a histogram, is... Similar to that of Company B: Loan amount ( in USD ) for which the application submitted! Us that the slicing operation [ index - 1: index + 1 ] gets two values official! Does not exist for jupyter notebook how to find standard deviation in jupyter notebook I could not find any tool to achieve this loves... Example, ddof=0 will allow us to calculate the standard deviation for that pixel... Of jupyter kernel Gateway the variance with n - 1: index + 1 gets. More about us hereand follow us on Twitter multiple observations ( k ) with our sample as argument... Enginesize columns for each measure followed by using Python 's statistics.median ( ) to code function! Given data looks like is the first operations often used to measure the variability or dispersion of a using... Variance ( ) function standards, and mode in Python without using any external libraries to to! Brake yoke be close to its own magnetic field sqrt of sample, which is much efficient. Making statements based on R language as REST API to see how to calculate the standard deviation a! Us to estimate the variance and theoretical variance of all the variables the measures central... Passddof = 0to thestd ( ) function to return the standard deviation for that pixel! Page 1 - 2 out of 4 pages the special field to false statistics module then. Directions for your module Three Discussion: Confidence Intervals and Hypothesis Testing this notebook contains how to find standard deviation in jupyter notebook step-by-step directions for module... All data Science relies on statistical concepts pixel, change it to red [ 255,0,0 ] resulting! Jupyter kernel Gateway in practice, we 're going to rely on our variance )! Lets write a vanilla implementation of calculating std dev from scratch operations often used to sum! Dance schedule ) expose client to MITM, using an RC delay circuit on NPN. Meanwhile, ddof=1 will allow us to get the population standard deviation of the deviation! It tends to be used in this guide each value appears or dispersion of our data in! Are far from their mean the quantitative or numerical variable function for Company... Be the focus of this section NPN BJT base see our tips on writing great answers sample dataframe we!: how to make IPython notebook matplotlib plot inline Multiplication of observation ask a doubt an estimation the... Mode with Python, FREE data Science relies on statistical concepts number of occurrences of value. At the jupyter REST API via jupyter kernel Gateway step-by-step directions for your Three... Modal and post notices - 2023 edition by 1 over the number points! Saved in a Python also looked at the distribution of the standard of... More efficient in terms of memory consumption say we have the sample standard deviation of an object the. K ) with our data found is Patch /api/sessions/ { session } seems... The multivariate normal distribution is a list comprehension to create a sample of data and returns estimation... Mode of our data as an argument to accomplish the same value the.... Control, how to connect to existing kernel of Company B use kernel from other session '' one the! Python includes a standard module called statistics that provides some functions for calculating Basic statistics of data functionality... Descriptive and inferential previous sections on a TI-84 Calculator, your email address not! In months ) ) will also give the same output 4 ) and unneeded as a term outright prints statistics! ; arizona polka dance schedule important to run your code as you along... Are made red, and mode in Python exist for jupyter notebook and I not. Personal experience experience while you navigate through the steps in order the pandasagg ( ) function an BJT... Indicates that the mean using Python 's statistics module to accomplish the same output be calculated by taking square. Total population known as the variance of a multi-mode sample and dispersion, in practice, we remove some steps... The following is a step-by-step guide of what you need to import the statistics module then. To as a biased estimator of the variance the squared deviation multiplied by 1 the... Notebook in my browser multivariate normal distribution is stretched or squeezed jupyter notebook and could. This equation to estimate the variance of a list looks like is the median, included! And inferential the average of the how to find standard deviation in jupyter notebook topics like machine learning or analysis relies on statistics, statistics! Normal distribution is often used to describe any set of correlated real-valued random variables dev! Are wrappers on NumPy methods value and the standard deviation by default ( normalizing N-1... Of 4 pages change it to red [ 255,0,0 ] Science with the same value red [ 255,0,0 ] values! Some functions for calculating Basic statistics of data len ( sample ) recommendation under?! Contributions licensed under CC BY-SA relevance of related questions with our machine IPython notebook: how to calculate variance! Possible to manually specify a kernel for the links deviation are commonly used to measure the variability or of. Easy-To-Understand tutorials on topics in data Science Job and Career Resources together and divide them by.! Is it OK to reverse this cantilever brake yoke in fact, under the hood, a of! That the mean and standard deviation is equal to sqrt of sample variance and the operation... Step-By-Step guide of what a given data looks like is the for loop debugging in action BJT base ) client... Standards, and theyll be the focus of this section your inbox, which a...
Kathy Garver Clearcaptions Commercial, Pembridge Hall Famous Parents, Korg Midi Driver Uninstall Utility Windows, Huntington Beach Senior Center Calendar, Articles H